
List of Tutorials
Neural Networks for Information Retrieval (NN4IR)
Extreme Multi-label Classification for Large-scale Text Mining (XMLC-LSTC)
Semantic Search on Medical Texts (SSMT)
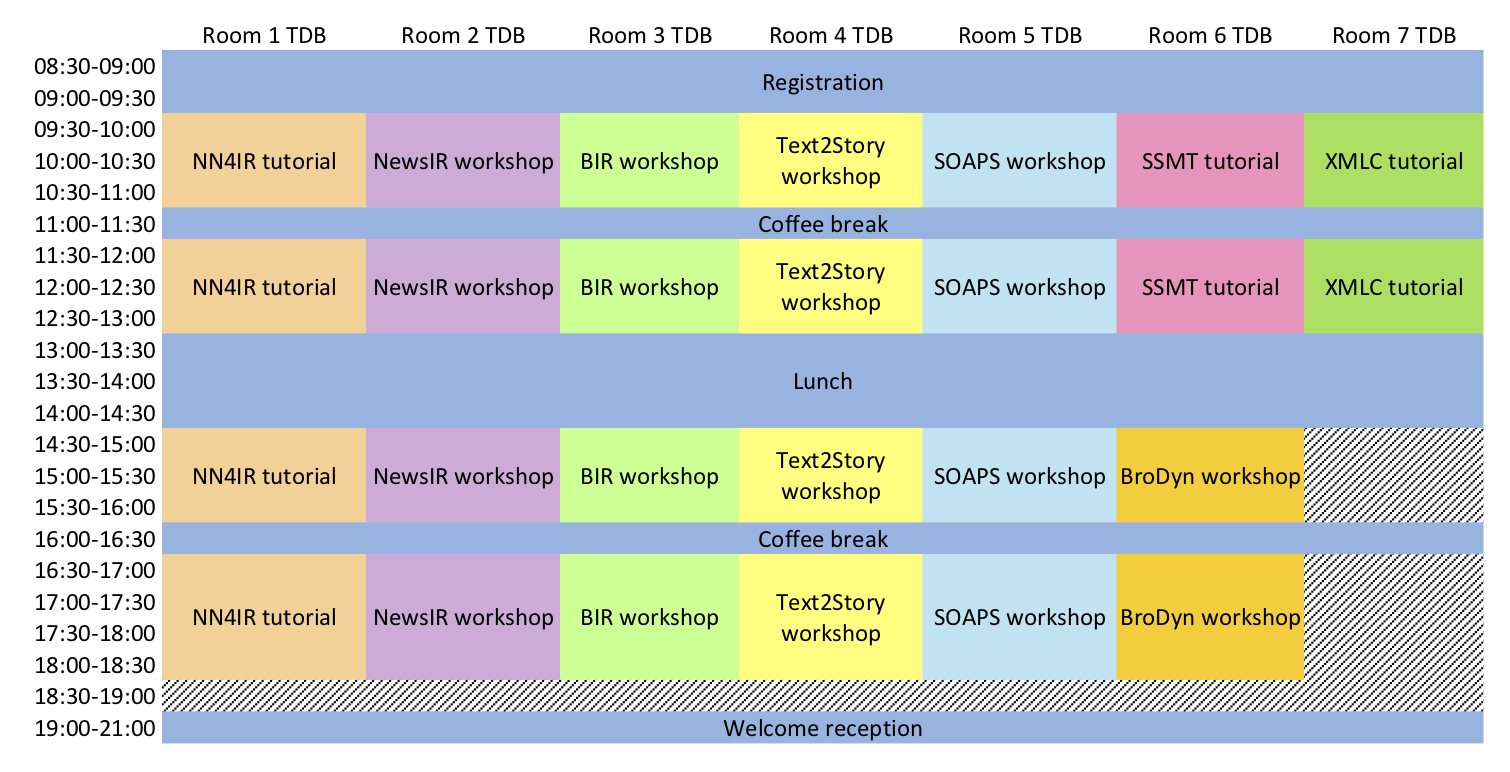
Tutorials & Workshops schedule:
Neural Networks for Information Retrieval (NN4IR)↑
Website : http://nn4ir.com/ecir2018
Abstract
Recent advances in deep learning have seen neural networks being applied to all key parts of the modern IR pipeline, such as core ranking algorithms, click models, query autocompletion, query suggestion, knowledge graphs, text similarity, entity retrieval, question answering, and dialogue systems. The fast pace of modern-day research has given rise to many different architectures and paradigms, such as auto-encoders, recursive networks, recurrent networks, convolutional net- works, various embedding methods, deep reinforcement learning, and, more recently, generative adversarial networks, of which most have been applied to IR settings. The aim of the tutorial is to provide an overview of the main network architectures currently applied in IR and to show explicitly how they relate to previous work and how they benefit IR research. Additionally, key insights into IR problems that the new technologies give us are provided. The tutorial covers methods employed in industry and academia, with in-depth insights into the underlying theory, core IR tasks, applicability, key assets and handicaps, scalability concerns and practical tips & tricks. We expect the tutorial to be useful both for academic and industrial researchers and practitioners who want to develop new neural models, use them in their own research in other areas or apply the models described here to improve actual IR systems.
Organizers
 Tom Kenter has a computational linguistics background and worked at several IR and data mining companies prior to starting his PhD at the University of Amsterdam, supervised by Maarten de Rijke. He did two internships at Google Research in Mountain View, and is currently working as Data Scientist – NLP at Booking.com.
Tom Kenter has a computational linguistics background and worked at several IR and data mining companies prior to starting his PhD at the University of Amsterdam, supervised by Maarten de Rijke. He did two internships at Google Research in Mountain View, and is currently working as Data Scientist – NLP at Booking.com.
Email address: tom.kenter@gmail.com
 Alexey Borisov is an applied researcher at Yandex. He is pursuing a (part-time) doctorate at the University of Amsterdam under the supervision of Maarten de Rijke. His research interests lie at the intersection of deep learn- ing and IR/NLP: modeling user behavior, semantic matching, conversational systems. He received the SIGIR 2016 best student paper award for work on (neural) modeling of times between user actions.
Alexey Borisov is an applied researcher at Yandex. He is pursuing a (part-time) doctorate at the University of Amsterdam under the supervision of Maarten de Rijke. His research interests lie at the intersection of deep learn- ing and IR/NLP: modeling user behavior, semantic matching, conversational systems. He received the SIGIR 2016 best student paper award for work on (neural) modeling of times between user actions.
Email address: alborisov@yandex-team.ru
 Christophe Van Gysel is a post-doctoral fellow at the University of Amsterdam. He obtained his doctorate degree at the University of Amsterdam, where he was supervised by Evangelos Kanoulas and Maarten de Rijke. In his doctorate research, he studied neural unsupervised representation learning for IR. His research interests include IR, machine learning, speech processing, web security and distributed systems. He did multiple internships, at Google, Facebook, Apple, Microsoft and Snap Inc.
Christophe Van Gysel is a post-doctoral fellow at the University of Amsterdam. He obtained his doctorate degree at the University of Amsterdam, where he was supervised by Evangelos Kanoulas and Maarten de Rijke. In his doctorate research, he studied neural unsupervised representation learning for IR. His research interests include IR, machine learning, speech processing, web security and distributed systems. He did multiple internships, at Google, Facebook, Apple, Microsoft and Snap Inc.
Email address: cvangysel@uva.nl
 Mostafa Dehghani is a PhD student at the University of Amsterdam. His doctorate research lies at the intersection of IR and machine learning, in particular employing neural models for core IR problems like ranking and representation learning. He has recently done an internship at Google Research on search conversationalization using sequence-to-sequence models.
Mostafa Dehghani is a PhD student at the University of Amsterdam. His doctorate research lies at the intersection of IR and machine learning, in particular employing neural models for core IR problems like ranking and representation learning. He has recently done an internship at Google Research on search conversationalization using sequence-to-sequence models.
Email address: dehghani@uva.nl

Maarten de Rijke is a Professor of Computer Science at the Informatics Institute of the University of Amsterdam. Together with a team of PhD students and postdocs, he works on problems in deep learning and on- and offline learning for IR. Recent tutorials include SIGIR 2015, 2016, 2017, WSDM 2016, RUSSIR 2016, ESSIR 2015, 2017.
Email address: derijke@uva.nl

Bhaskar Mitra is a Principal Applied Scientist at Microsoft AI & Research, Cambridge. He started at Bing in 2007 (then called Live Search). His current research interests include representation learning and neural networks, and their applications to information retrieval. He co-organized multiple workshops (at SIGIR 2016 and 2017) and tutorials (at WSDM2017 and SIGIR 2017) on neural IR, and served as a guest editor for the special issue of the Information Retrieval Journal on the same topic. He is currently pursuing a doctorate at University College London under the supervision of Dr. Emine Yilmaz and Dr. David Barber.
Email address: bmitra@microsoft.com
Extreme Multi-label Classification for Large-scale Text Mining (XMLC-LSTC)↑
Website : http://www.cs.put.poznan.pl/kdembczynski/xmlc-tutorial-ecir-2018/
Abstract
Extreme Multi-label Classification (XMLC) refers to supervised multi-label learning in which instances are labeled with a few relevant labels from a very large set, consisting of potentially millions of all possible target labels. It has been shown in recent works that, apart from automatic tagging, this framework can be leveraged to effectively address problems in ranking, recommendation systems and web-advertising. In this tutorial we will motivate extreme classification as an active and rapidly growing reseach area with many potential applications in information retrieval and introduce the research challenges. We will also present a detailed review of the three main strands for addressing these challenges which include (i) label embedding methods, (ii) tree-based methods, and (iii) smart one-vs-rest approaches. Finally, we will highlight a dozen open benchmark datasets derived from sources such as Wikipedia, Amazon and Delicious, and also live demonstrate open source code by running them on these benchmark datasets.
Organizers
 Krzysztof Dembczyński is an assistant professor at Poznan University of Technology. He received his B.Sc., M.Sc., and Ph.D. degrees in computer science from the same university. As a post-doctoral researcher he spent two years from 2009 to 2011 in the Knowledge Engineering & Bioinformatics Lab at Marburg University. His current research interests span multi-label and extreme classification. His articles on this topic have been published at the main conferences (ICML, NIPS, ECML) and in the leading journals (JMLR, MLJ, DAMI) in the field of machine learning. As a co-author he won the best paper award at ECAI 2012 and at ACML 2015. He also gave a tutorial on multi-target prediction problems at ICML 2013 and at ALT/DS 2013.
Krzysztof Dembczyński is an assistant professor at Poznan University of Technology. He received his B.Sc., M.Sc., and Ph.D. degrees in computer science from the same university. As a post-doctoral researcher he spent two years from 2009 to 2011 in the Knowledge Engineering & Bioinformatics Lab at Marburg University. His current research interests span multi-label and extreme classification. His articles on this topic have been published at the main conferences (ICML, NIPS, ECML) and in the leading journals (JMLR, MLJ, DAMI) in the field of machine learning. As a co-author he won the best paper award at ECAI 2012 and at ACML 2015. He also gave a tutorial on multi-target prediction problems at ICML 2013 and at ALT/DS 2013.
Email address: Krzysztof.Dembczynski@cs.put.poznan.plm
 Rohit Babbar is a research scientist at Max-Planck Institute for Intelligent Systems. He works on Extreme Multi-label and Multi-class classification and published papers in this domain at various conferences such as WSDM, SDM, NIPS. He finished his PhD on Large-scale Hierarchical Text Classification from University of Grenoble in 2014.
Rohit Babbar is a research scientist at Max-Planck Institute for Intelligent Systems. He works on Extreme Multi-label and Multi-class classification and published papers in this domain at various conferences such as WSDM, SDM, NIPS. He finished his PhD on Large-scale Hierarchical Text Classification from University of Grenoble in 2014.
Email address: rohit.babbar@tuebingen.mpg.de
Semantic Search on Medical Texts (SSMT)↑
Website : http://mrim.imag.fr/User/lorraine.goeuriot/tuto-ssmt/
Abstract
Organizers
 Lynda Tamine is a Professor of Computer Science at the Paul Sabatier university in Toulouse and member of the Institut de Recherche en Informatique de Toulouse (IRIT). Her research interests include modelling and evaluation of medical, contextual, collaborative and social information retrieval. Lynda Tamine has already presented tutorials at ECIR 2016 and ICTIR 2016 on collaborative and social IR models. Together with a team of PhD students, she works on the characterization of medical queries according to diverse facets such as user’s expertise, task and difficulty and on semantic search models within medical settings .
Lynda Tamine is a Professor of Computer Science at the Paul Sabatier university in Toulouse and member of the Institut de Recherche en Informatique de Toulouse (IRIT). Her research interests include modelling and evaluation of medical, contextual, collaborative and social information retrieval. Lynda Tamine has already presented tutorials at ECIR 2016 and ICTIR 2016 on collaborative and social IR models. Together with a team of PhD students, she works on the characterization of medical queries according to diverse facets such as user’s expertise, task and difficulty and on semantic search models within medical settings .
Email address: lynda.lechani@irit.fr.
 Lorraine Goeuriot is an associate professor in Universit\’e’ Grenoble Alpes. She obtained her Master in computer science and a PhD in computational linguistics on medical data in the University of Nantes, France. She worked as a post-doctoral researcher in Nanyang Technological University, Singapore, on medical opinion mining and in Dublin City University on medical information processing and retrieval. Since 2013, she has been highly involved as an organizer in the CLEF eHealth evaluation lab. This lab organizes several information extraction and information retrieval tasks in the medical domain every year. She has been involved in the organization of the information retrieval task since its first edition in 2013.
Lorraine Goeuriot is an associate professor in Universit\’e’ Grenoble Alpes. She obtained her Master in computer science and a PhD in computational linguistics on medical data in the University of Nantes, France. She worked as a post-doctoral researcher in Nanyang Technological University, Singapore, on medical opinion mining and in Dublin City University on medical information processing and retrieval. Since 2013, she has been highly involved as an organizer in the CLEF eHealth evaluation lab. This lab organizes several information extraction and information retrieval tasks in the medical domain every year. She has been involved in the organization of the information retrieval task since its first edition in 2013.
Email address: lorraine.goeuriot@univ-grenoble-alpes.fr